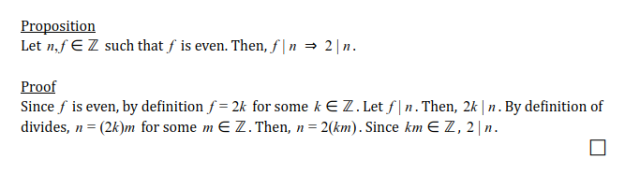As I’ve mentioned previously, I taught myself how to code a few years ago. I’ve learned a lot more since then, but I’m always learning. The other day, I had an assignment for another course that involved going back and refactoring old code. Since it was so bad, I’d like to discuss it.
Concept
The code itself is a terminal based Java calculator. I imagine it was really tricky for me at the time considering the way in which I implemented it. I didn’t know about the static keyword nor about how to use methods. This serves as a great example of what not to do:
The Original Code
Now, the code itself is so horrendously bad that I have to get creative to even display it. So here’s a few entertaining lines. Keep in mind the entire program is within the main method:
int load; double num1, num2, ans; boolean on, autoclose, autocontinue, loading, numchecking, divide, multiply, add, subtract, other, help; String in, in2, in3, in4, in5, operation, fa, status1, status2, status3; char op;
Now, a sane person might ask “Why are there so many variables and why are many of them named so badly?” Well the reason is because I didn’t use methods. I used variables to separate control flow. I also find it funny that I had a String for every user input rather than just reusing one, as well as the fact that I declared all variables at the top for no reason. Here’s an example of that horrible control flow in action:
in = input.next();
if (in.equals("/")) {
divide = true;
numchecking = true;
operation = "divide";
fa = "by";
op = '/';
}
else if (in.equals("*")) {
multiply = true;
numchecking = true;
operation = "multiply";
fa = "by";
op = '*';
}
I would ask for input, set these variables, and then later on:
if (numchecking) {
Thread.sleep(1000);
System.out.println("Enter your first number.");
num1 = input.nextDouble();
System.out.println("Enter another number to " + operation + " " + fa + " " + num1);
num2 = input.nextDouble();
if (divide) {
ans = num1 / num2;
}
if (multiply) {
ans = num1 * num2;
}
if (add) {
ans = num1 + num2;
}
if (subtract) {
ans = num1 - num2;
}
Thread.sleep(3000);
System.out.println("Calculating...");
Thread.sleep(1000);
System.out.println(num1 + " " + op + " " + num2 + " = " + ans);
I have no idea why I used if else previously but not here. I can understand I didn’t know how to use a switch statement yet I guess. Anyway, I used Thread.sleep() to add artificial delay for some reason in the program. This code I’ve shown is pretty tame honestly. Notice the line counts. I recommend taking a look at the original source code so you can really appreciate how horrible it is. Unfortunately, I had to convert the .java file to a .docx file to upload it to WordPress:
The Refactoring Process
I find myself fall into the same hole: When I realize I can do something in a better way but it’s large and intimidating, I prefer to start from the beginning rather than modifying the current product. Sometimes, that is extremely useful and you just need a solid clean start. However, often that’s overkill and wastes time. I tend to do that even in video games.
As an example, one of my all time favorite games is Factorio which is an indie game about building factories and trying to automate everything. The goal of the game is to get the game to play itself. Anyway, I have over 500 hours in this game and I haven’t actually reached the end goal of launching a rocket. It’s not because I don’t know how to do it or I die too quickly. It’s because I’m never satisfied with my factory layout or my world generation settings. When it comes to world generation, I do actually have to start over. When it comes to factory layout, I could take the time to manually replace the entire layout and keep my current research. Despite that, I almost always start over.
The saving grace with code is that, when its scale is manageable, it can be incredibly fun and relaxing to refactor. Sometimes it’s tough to get started but once you do, it’s a really fun time. I honestly had less trouble refactoring as I did with the assignment itself. The assignment wanted me to make a change based on a guide. Make the change, write it down, and continue. However, I fell into refactoring and made change after change extremely quickly. With code this bad, it was really easy to just aim at one thing and make 40 changes that all fit into unique categories. So I prioritized refactoring the code well over documenting it well.
Virtually all of those variables I had before are gone. Here is the refactored beginning of the code:
private static final String[] OPERATORS = {"+", "-", "*", "/"};
private static Scanner scanner;
private static boolean autoContinue;
private static boolean autoClose;
private static boolean continueOnce;
public static void main(String[] args) {
boolean programIsOn = true;
You’ll notice I made use of static variables. I only have one variable in the main method and it controls the loop of the program. Other variables are now in methods or simply don’t exist. I even created an array of operators to allow for easier expansion of functionality later on, despite the fact that I’ll almost certainly never come back to this project. I also have 3 booleans on 3 separate lines. This is my personal preference, but with only 3, I would understand simply writing: private static boolean autoContinue, autoClose, continueOnce; I just tend to lean on keeping things on separate lines. Although now that I’ve written that, I kind-of do prefer that. Although it would mess up the width aesthetic going on because it’s such a wide line.
Before, I showed part of how I took in user input and managed arithmetic operations. I set a bunch of variables and handled it later. Here’s how I manage it now:
private static void handleOperations() {
String operation = scanner.next();
System.out.println();
if(isArithmeticOperator(operation)) {
arithmeticOperation(operation);
return;
}
switch(operation) {
case "help":
help();
continueOnce = true;
break;
case "exit":
autoClose = true;
break;
default:
System.out.println("Sorry, I don't understand that operation. Try again.");
continueOnce = true;
}
}
I created a method to handle it that is called in the main loop. It has good variable names, uses a switch statement, and calls methods that have descriptive names. It could be better but it is leagues better than what it was before. Originally in the refactoring process, I had:
private static boolean doUserRequestedMethod() {
switch(scanner.next()) {
case "/":
divide();
break;
case "*":
multiply();
break;
case "+":
add();
break;
case "-":
subtract();
break;
case "help":
help();
return true;
case "exit":
autoClose = true;
break;
default:
System.out.println("Sorry, I don't understand. Try again.");
return true;
}
return false;
}
It returned a boolean value to allow the loop to continue if it needed to, such as if the user entered an unknown command. I replaced that with global (static) variables to control that. I renamed the method for clarity, and I created a single arithemticOperation() method to avoid code repetition. However, that function itself needed a switch statement, so rather than check the operation twice, I split off the arithmetic operations from the original switch statement in a way that allowed me to add more arithmetic operations in the future. I’m pretty happy with that solution.
Lastly, since I showed how the numbers are calculated originally, I should show that in the refactored version. First I have to check if the input was for an arithmetic operation:
private static boolean isArithmeticOperator(String potentialOperator) {
for(String operator : OPERATORS) {
if(potentialOperator.equals(operator))
return true;
}
return false;
}
This was part of why I created the OPERATORS array, so that I could avoid a long boolean of &&s. Then for the actual calculation:
private static void arithmeticOperation(String operator) {
System.out.println("Enter a number: ");
double leftOperand = scanner.nextDouble();
String partialEquation = leftOperand + " " + operator + " ";
System.out.print(partialEquation);
double rightOperand = scanner.nextDouble();
double result = leftOperand;
switch(operator) {
case "/":
result /= rightOperand;
break;
case "*":
result *= rightOperand;
break;
case "-":
result -= rightOperand;
break;
case "+":
result += rightOperand;
break;
}
System.out.println(partialEquation + rightOperand + " = " + result);
}
Again, you’ll find decent variable names and a more clear control flow. Obviously this code isn’t flawless but that’s not the real goal in refactoring. The point of refactoring is to create an improvement. You’ll never have perfect code, but you can always improve your code. This is pretty analogous to life itself. Recognize the value and functionality currently there, recognize that you will never be perfect, but always aim to be better.
Here is the current state of the refactored code. It’s honestly amazing how much better it is:
Conclusion
Refactoring is not something to be feared; it should be enjoyed. There is something very relaxing about it if you enter it with the right mentality. Focus on small things you can easily tackle that would make a big improvement and do that. As you slowly cross off changes you need to make, it’ll become more manageable and more readable. In that program above, I cut the number of lines in half after refactoring. I can actually read it and understand what it’s doing. It should be satisfying to go through and make progress towards simplicity and organization. You just have to want it.
From the blog CS@Worcester – The Introspective Thinker by David MacDonald and used with permission of the author. All other rights reserved by the author.