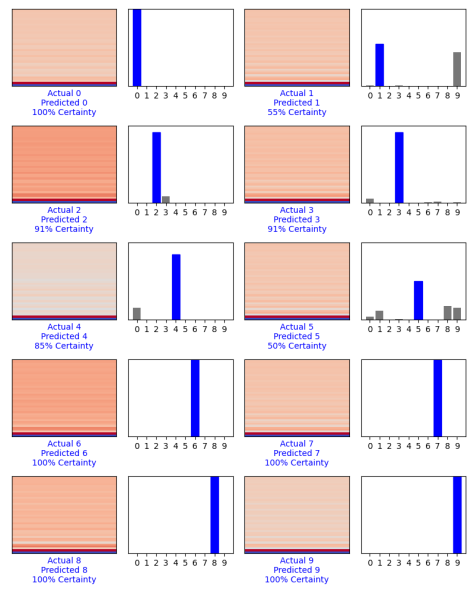
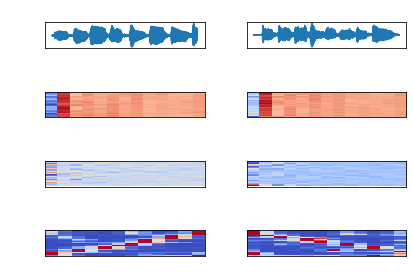
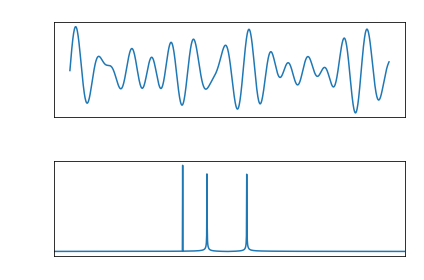
With this year’s independent study presentation complete and the semester’s coming to a close, I have a project that is working. Naturally, there’s a lot more I wish I could have done. But I’ve learned a lot not only about individual technologies, but also how to plan a large project and schedule tasks.
Setting deadlines for certain portions of the project was helpful, but I did deviate from the schedule a bit in order to get more-important parts done, or prerequisite issues that were unexpectedly necessary. Some flexibility is certainly required when entering into a project without a working knowledge of the technologies at hand.
I love throwing myself into things that I know will be difficult, and that’s kind of what I was going for in this project. Turning big problems into smaller, manageable problems is one of the main reasons I enjoy software. But it’s a balancing act, because I was essentially throwing myself into 3 big problems: Learn signal processing; learn machine learning; implement a mobile application. There were a few weeks of struggling with new technologies for more hours than I had planned, and knowing that I was barely scratching the surface of only one of these big problems caused considerable stress. At times, I thought there would be no way I could get a single portion done, let alone all three.
But somehow each week I got over a new learning hump just in time to implement my goal for the week, while concurrently doing the same for my capstone sprints. Deadlines are a beautiful thing. I did a speech in my public speaking class in my first year that discussed Parkinson’s law, which says work will expand to fill the time available for its completion. This idea has followed me ever since and has proven to be true.
In preparing my presentation in the last couple of weeks, I found a couple of issues and had a couple realizations on how I could do things differently (read: better). I added some of them as I went along, and I was tempted to completely revamp the machine learning model before my presentation. Instead of the inevitable all-nighter it would have required, I managed to restrain myself and save it for the future. But this shows the importance of presenting your work as you go along, as one does in a Scrum work environment. Writing about and reflecting on issues and solutions in a simple way forced me to re-conceptualize things, both in my blog posts as I went through the semester, and in my final presentation.
While I had guidance from my advisor on how to approach and complete the project, planning and implementation was on me. There were definitely pros compared to my capstone’s team project. For example, I knew every change that was made and I had to understand all the working parts. Getting things done was mostly efficient because I only had to coordinate my own tasks. However, in my capstone I was able to bounce ideas off of team members who could provide a different perspective when we both understood the language or framework at hand. Delegating tasks also made it easier to completely understand the subtle details that allows for efficient use of a technology. Both of these experiences taught me transferable skills which I’ll be able to use in the future in solo and team projects.
From the blog CS@Worcester – Inquiries and Queries by James Young and used with permission of the author. All other rights reserved by the author.