When testing a software product the testers need access to some amount of information. The can be given access to just the finished product, just the code, or both. In each case the type of testing can vary.
Black-box testing refers to testing software where you have not been given the source code. In most cases the tested would be given a set of specifications. The tested the preform test on the product and ensure it complies with the specifications. The main way in which black box testing works is by providing input and verifying the output is what is expected.
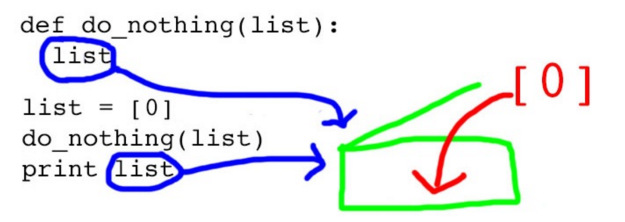
With white-box testing the testers have access to the source code. This means the they can examine how the code works. This can prove to be more complex but allows for much more thorough testing. This is where unit testing can really work and test cases can be written to test the code. Metrics can also be generated to show how much of the code was actually covered by test.
The third options involves a little of both categories, this is known as gray-box testing. In most cases involving gray-box testing the tested don’t have access to the source code but do have some knowledge of the inner workings of the program. One example of this would be a team that understands the formulas and methods used by software. This allows them to create more specific test than black-box testing that can target areas that are more likely to have issues. This is a good place for boundary value testing.

![]()
From the blog CS@WSU – :(){ :|: & };: by rmurphy12blog and used with permission of the author. All other rights reserved by the author.