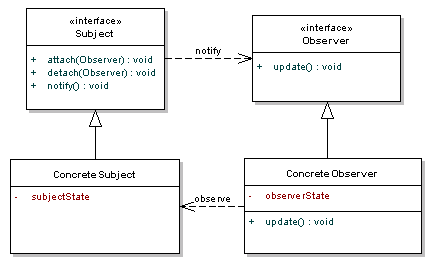
http://sahandsaba.com/nine-anti-patterns-every-programmer-should-be-aware-of-with-examples.html
This blog post covers 9 anti-patterns that are common in software development.
- Premature Optimization – Optimizing before you have enough information to make conclusions about where and how to do the optimization. This is bad because it is hard to know exactly what the bottleneck will be before you have empirical data.
- Bikeshedding – Spending excessive amounts of time on subjective issues that are not important in the grand scheme of things. This anti-pattern can be avoided by prioritizing reaching a decision when you notice it happening.
- Analysis Paralysis – Over-analyzing so much that it prevents action and progress. A sign that this is happening is spending long periods of time on deciding things like a project’s requirements, a new UI, or a database design.
- God Class – Classes that control many other classes and have many dependencies and responsibilities. These can be hard to unit-test, debug, and document.
- Fear of Adding Classes – Fear of adding new classes or breaking large classes into smaller ones because of the belief that more classes make a design more complicated. In many situations, adding classes can actually reduce complexity significantly.
- Inner-platform Effect – Tendency for complex software systems to re-implement features of the platform they run in or the programming language they are implemented in, usually poorly. Doing this is often not necessary and tends to introduce bottlenecks and bugs.
- Magic Numbers and Strings – Using unnamed numbers or string literals instead of named constants in code. This makes understanding the code harder, and if it becomes necessary to change the constant, refactoring tools can introduce subtle bugs.
- Management by Numbers – Strict reliance on numbers for decision making. Measurements and numbers should be used to inform decisions, not determine them.
- Useless (Poltergeist) Classes – Classes with no real responsibility of their own, often used to just invoke methods in another class or add an unneeded layer of abstraction. These can add complexity and extra code to maintain and test, and can make the code less readable.
I chose this blog because anti-patterns are one of the topics on the concept map for this class and I think they are an interesting and useful concept to learn about. I thought this blog was a very good introduction to some of the more common anti-patterns. Each one was explained well and had plenty of examples. The quotes that are used throughout the blog were a good way of reinforcing the ideas behind each anti-pattern. I will definitely be keeping in mind the information that I learned from this blog whenever I code from now on. I think this will help me write better code that is as understandable and bug-free as possible.

![]()
From the blog CS@Worcester – Computer Science Blog by rydercsblog and used with permission of the author. All other rights reserved by the author.