
What is the Decorator Design Pattern?
The Decorator pattern applies when there is a need to dynamically add as well as remove responsibilities to a class, and when the sub-classing would be impossible due to the large number of sub-classes that could result. Also, use it when you want the capabilities of inheritance with sub-classes, but you need to add functionality at run time.
Intent
- Attach additional responsibilities to an object dynamically.
- Decorators provide a flexible alternative rather than making many subclasses to extend functionality.
- Client-specified embellishment of a core object by recursively wrapping it.
- Wrapping a gift, putting it in a box, and wrapping the box.
Discussion
Say, you are working on a UI and you want to add borders and scroll bars to your windows. You could define the inheritance like… Window class interface, then you have concrete objects WindowWith_Scrollbar, WindowWith_Border etc.. This type of architecture creates a lot of subclasses and not much room for modularity. It will be hard to change the concrete classes if you want to add some additional functions to them.
The Decorator pattern suggests giving the client the ability to choose what features they want. There might be a problem of chaining features together to produce custom objects as well. The solution to such problem is to encapsulate the original object inside an abstract wrapper interface. Both the decorator objects and the core object will inherit from the abstract interface. Then the interface uses recursive composition to allow an unlimited number of decorator to be added to each core object. One thing to note is that the interface must remain constant when successive layers are specified using the decorator pattern.
The decorator pattern hides the core components of the objects inside the decorator object. Trying to access the core object directly would be a problem.
UML Diagram
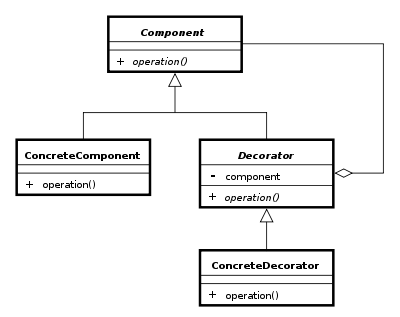
Example
One example is making a pizza ordering system. You can use the decorator pattern to implement a simple pizza ordering system by creating a pizza(component) and a plain pizza(Concrete Component) that is just the base or dough. Then the decoratorPizza(Decorator) which has the plain pizza and other functions. Lastly, the toppings(Concrete Decorators) for your pizza like: mozzarella, the sauce, pepperoni, etc.
In this example, you have an interface pizza and a plain dough. The decorator then adds the desired toppings to the pizza.
Conclusion
I chose this particular topic since we are creating a simple web app for scheduling classes. I thought that it was helpful since we might be adding pop up windows to our web app.
The Decorator Pattern is useful when you see yourself making something that is extensible and where you can interchangeably choose which components/functions you want on your object. I think that with the decorator pattern, there is a lot of potential when using it. You could create something that has many functionality and is still easily changeable.
source: decorator pattern

![]()
From the blog cs-wsu – Computer Science by csrenz and used with permission of the author. All other rights reserved by the author.





