During this sprint in my software development capstone class, my team and I tried to make some progress on establishing our offline data capture service. Before creating our tasks, we organized our team’s trello board to be a bit better. We changed the layout of our board by creating different columns that were categorized by our names to indicate who was in charge of doing a specific task that was assigned to them. We did this because it could make us as team to better understand who was doing what, and what was currently worked on in this sprint.
The team and I attempted to find out more ideas from the people at AMPATH through the communication with Jonathan Dick. We felt that we needed to get some ideas to further progress at our offline data capture or else we wouldn’t know what to do during this sprint. One question that I had asked to JD pertained to a GUI, which he wanted that indicates and separates offline data from the online data through our service. We are still currently figuring out on how to create the GUI. Other tasks that we attempted were:
- If dealing with CORS issues, create a desktop shortcut loading an instance of Chrome disabling web security.
- Create balsamiq diagrams outlining current and anticipated implementations of offline-capturing the OpenMRS / ETL data.
- Write tests for our implementations.
- Design the HTML part of an offline component that will be used for our GUI. Should be similar to the layout of the AMPATH Patient Search Component.
- Collaborate with the encryption team regarding the process of how our captured data ought to be encrypted.
- Touch base with all teams (encryption, offline-storage, and login) regarding their overall progress.
- Create a mock diagram in Balsamiq illustrating an idea of a GUI that presents the captured data in a meaningful way.
- Develop mock diagram in Balsamiq where a “Doctor/Provider” can pick and choose what patients to sync.
All of these tasks are still ongoing, leading into the next sprint. I felt that we were unable to complete any of these tasks within this sprint because we spent most of the time asking questions. I would admit that there were times where we were lost because we weren’t communicating enough to JD. However, one task that we got done was:
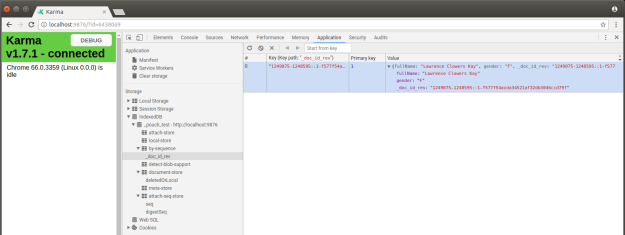
- Get ALL patients in the database (not just those with “test” in the name). Store each patient results into an array, then iterate through it to store each into separate files in PouchDB.
What we learned from attempting these tasks was that it taught us to constantly communicate with AMPATH to develop a smooth transition from task to task so we don’t get stuck and waste time on what to do next. Communicating with AMPATH and asking questions to them will help us develop ideas on how to proceed with a task to validate what we are doing is what the people at AMPATH and JD wants. This was the main thing we learned from our mistake. This can be applied in other situations because in the software development career, communication is one of the most important things to do for this particular reason. If there is not constant communication, whether it be to your teammates or anyone in the workplace, work can become difficult and you can become unaware of what to do, which can further delay the project or task from getting done.
The effort that my team put into this sprint was sufficient despite the incomplete tasks. Everyone still tried to attempt at something even though we were still stuck on how JD and the people at AMPATH wanted our Offline Data Capture service to look like. For this sprint as an individual I mainly tried to still gather ideas and find a suitable encryption implementation for the AMPATH code and I think that using crypto.js wouldn’t work efficiently, so I decided to keep on researching. I also talked to the encryption team and found out that they ran into some impediments as well on developing their encryption service. Moving forward, my team and I need to communicate more effectively with the other teams as well as with JD and AMPATH. Doing this will help us work better.
From the blog CS@Worcester – Ricky Phan by Ricky Phan CS Worcester and used with permission of the author. All other rights reserved by the author.