This Sprint was a good one. We gained traction last sprint and kept that that going this sprint as well. The momentum was not fully there as Spring Break was a bit of a speed bump to getting in to the flow of the project, and then afterward many end of semester projects came up that took my time. But either way, by the end we had the basic bare bones of an offline data storage service, a good stopping for next sprint to continue and hopefully finish off.
I continued experimenting with PouchDB this sprint, still on a separate angular project than the ng2-amrs project. This was mostly to avoid the hassle of installing and getting PouchDB working on the ng2-amrs project, as I had seen and heard frustrations from my team and others. This also let me worry solely on getting PouchDB working in a project and creating a successfully working angular project service to handle the logic of the offline storage, with methods for adding and getting documents from the PouchDB database.
I realized after a meeting with my team one day that the formatting of my code was different than the project, and so I copied the ng2-amrs projects tslint.json file into my own to make sure transferring any code I used would be easy and issue free. I fixed my function calls to use the recommended “ => “. After I made the code still work and formatted correctly, I created a new service called simply “offlineStorage”. It had a cunstructor that created a new PouchDB database, and just two methods, one to add a document to the database and one to get a document back.
The code in these methods was reworked code from the examples on PouchDB’s website, with added console logs to see the results. Then to actually test the service, I modified the .spec file for it by adding more tests than the default one. This part was done along with my entire team across two of our in person meetings. We were able to confirm that the service actually created a database, added documents of given data with a given id, and got documents back with a desired id.
The main issue that popped up with the tests were the fact I and my team were wondering how to interact with the documents received by using the get command. When checked the type of the response, it simply stated it was an object. I was not sure how to check the contents of the document and see if it was the correct one. On the last meeting our professor helpfully suggested we see if it was a JSON object, which it was. I felt a bit silly, but now with that issue solved, working with the documents we get from PouchDB and possible ones we add into PouchDB should go much smoother.
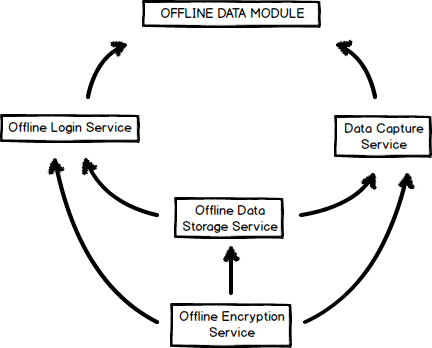
During this sprint, occasionally conversations would veer into discussing how we would receive the data from an mrs server and what kind of format the data would be. But after discussing it among ourselves, a helpful diagram drawn up by our team mate Connor showing our role in the overall project and we decided to only worry about our task, offline storage, and nothing else. So we are going to focus completely on fleshing out the service that will handle offline storage tasks using PouchDB. With a narrowing of possible tasks, the division of work for the next step should be very clear.
I feel like it took a bit, but we cleared another hurdle. After this we should speed up next sprint, and hopefully have a completed service that can handle offline storage and a pull request to the master ng2-amrs project by the end of next sprint.
From the blog CS@Worcester – Fu's Faulty Functions by fymeri and used with permission of the author. All other rights reserved by the author.