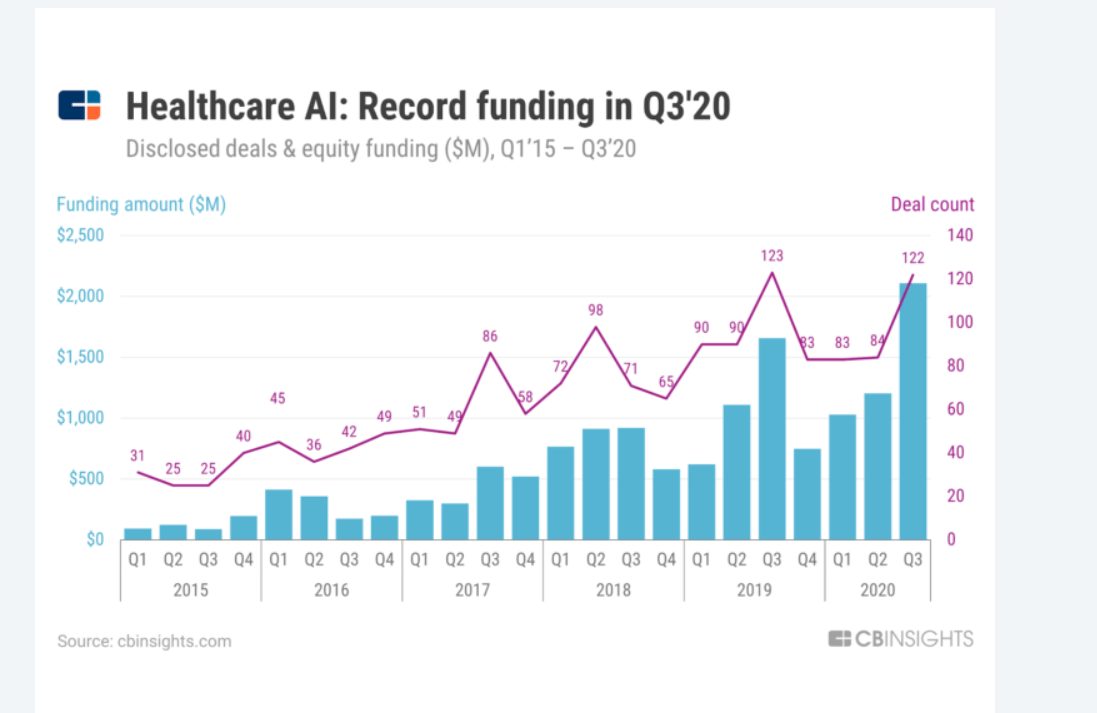
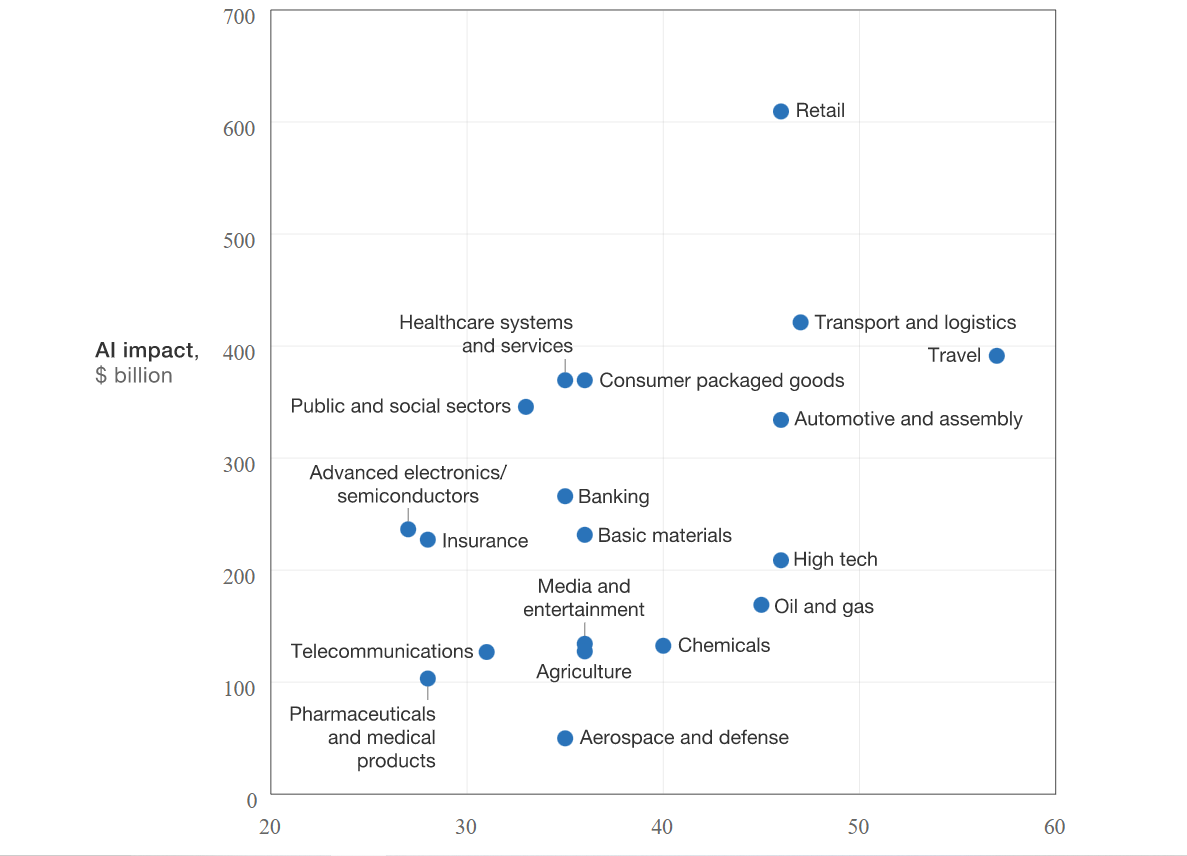
SOLID
SOLID is an acronym that stands for five key design principles: Single responsibility principle, Open-closed principle, Liskov substitution principle, Interface segregation principle, and Dependency inversion principle. All five are used by software engineers and provide significant benefits to developers.
Principles of SOLID:
- SRP – Single Responsibility Principle
SRP states that, “a class should have one, and only one, reason to change.” Following this principle means that each class does only one thing and each class or module is responsible for only one part of the program functionality. For simplicity, each class should solve only one problem.
Single responsibility principle is a basic principle that many developers already use to create code. It can be used for classes, software components, and sub-services.
Applying this principle simplifies testing and maintaining the code, simplifies software implementation, and helps prevent unintended consequences of future changes.
- OCP – Open/Closed Principle
OCP states that software entities (classes, modules, methods, etc.) should be open for extension, but closed for modification.
Practically this means creating software entities whose behavior can be changed without the need to edit and compile the code itself. The easiest way to demonstrate this principle is to focus on the way it does one thing.
- LSP – Liskov Substitution Principle
LSP states that “any subclass object should be substitutable for the superclass object from which it is derived”.
While this may be a difficult principle to put in place, in many ways it is an extension of a closed principle, as it is a way to ensure that the resulting classes expand the primary class without changing behavior.
- ISP – Interface Segregation Principle
ISP principle states that “clients should not be forced to implement interfaces they do not use.”
Developers do not just have to start with an existing interface and add new techniques. Instead, start by creating a new interface and then let your class implement as many interactions as needed. Minor interactions mean that developers should prefer composition rather than legacy and by separation over merging. According to this principle, engineers should work to have the most specific client interactions, avoiding the temptation to have one large, general purpose interface.
- DIP – Dependency Inversion Principle
DIP – Dependency Inversion Principle states that “high level modules should not depend on low level modules; both should depend on abstractions. Abstractions should not depend on details. Details should depend upon abstractions”
This principle offers a way to decouple software modules. Simply put, dependency inversion principle means that developers should “depend on abstractions, not on concretions.”
Benefits of SOLID principle
- Accessibility
- Ease of refactoring
- Extensibility
- Debugging
- Readability
REFERENCES:
From the blog CS@Worcester – THE SOLID by isaacstephencs and used with permission of the author. All other rights reserved by the author.