
At the beginning of this sprint cycle my team and I thought we had a pretty good handle on what we needed to accomplish and how we were going to do it. In the previous sprint cycle we had figured out how to instantiate a pouchDB in browser database as well as add elements and get them back through the console. To test whether we could get pouchDB working within the ng2-amrs application we added some code the app.component.ts file. Once we were sure that pouchDB could work in the application we moved forward in writing the pouchDB offline storage service. However, we were trying to incorporate open-mrs api calls in our offline storage service which proved to be much more complicated than we originally though. To remedy this problem we decided to break it into smaller pieces and Conor drew up a diagram in balsamic to help us not over think what we needed to accomplish. Here is the diagram Conor made:
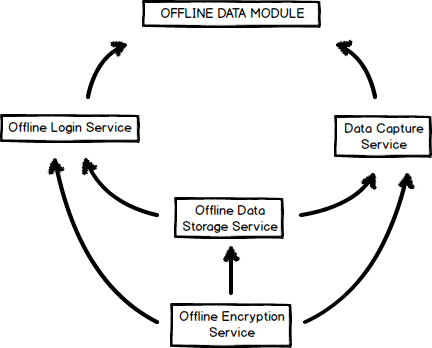
In this diagram my team’s responsibility is the “Offline Data Storage Service.” Instead of trying to do everything at once, we decided we just needed to write a service that will store JSON objects in an in-browser database. By narrowing the scope of what we needed to get done to one task we have been able to make more meaningful progress.
During our team meetings we were able to get started in writing an add method for our offline storage service as well as corresponding unit tests. Through writing this method and it’s corresponding unit tests we found that pouchDB databases use JSON objects by default making our job a little easier. We have not pushed any new code onto our group’s GitHub page but that will be one of the first steps we take in starting the next sprint cycle.
In our last team meeting we were able to get everyone caught up on where we were at in the project and assign specific tasks to each group member going forward. After narrowing our scope down we decided that the main methods we needed to focus on for our offline storage service included add, put, delete, and clear. The add method will store elements in JSON format in the pouchDB database. As for the put method, it should take in the id of an element already stored in the database and alter the information of that element. Finally, the delete method will take in the id of an element in the database and remove the element, this method will also return the JSON object that was deleted. We also discussed implementing a clear method that could erase all data stored in the pouchDB database but we have not decided whether or not this function will be necessary to accomplish our goals.
Moving forward, my team and I will have to contact the Ampath developers and ask if they agree with the direction we are heading in. We will also need to communicate with other teams to make sure that our service can coexist/ be implemented in the other teams’ code. If everything goes as planned, we should have a functional offline storage service by the end of the next sprint cycle and we should also be able to start piecing together our piece of the project with other teams’.
From the blog CS@Worcester – Caleb's Computer Science Blog by calebscomputerscienceblog and used with permission of the author. All other rights reserved by the author.
