For this blog I will be taking a look at Angular Classes vs Angular Interfaces in Typescript. Angular Classes and Interfaces facilitate not just object-oriented programming but is also used for type-checking in Typescript. As we all should know, a class is generally a blueprint that can be used to create objects that share the same properties or methods. While an interface is a group of related properties or methods that help to describe an object, an interface however does not provide implementation or initialize an object.
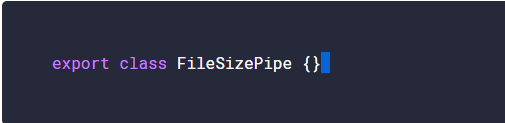
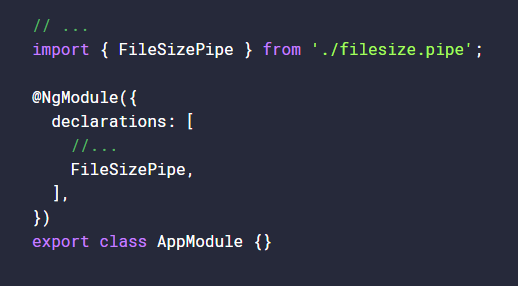
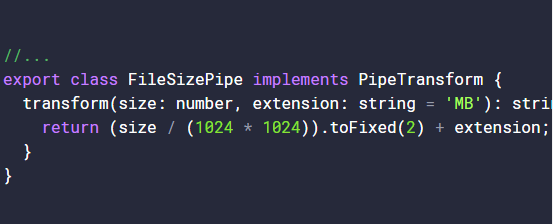
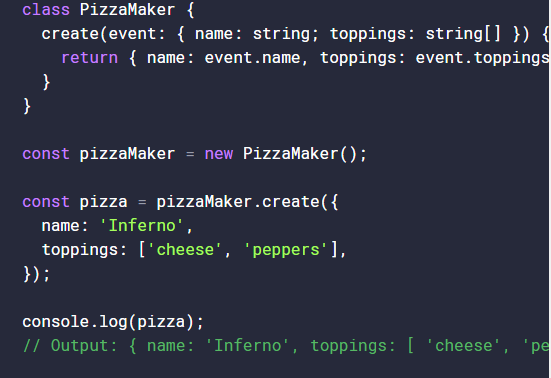
Using a class with Typescript boosts the Javascript classes with the power of typechecking and static properties. Whenever the code is transpiled to a target Javascript code, the transpiler keeps the class code present throughout all phases of the code. Classes are looked at as object factories and help to define the blueprint for what an object will look like and should act like. When you create an instance of this class, the object has defined functions and properties. In the example, we create a PizzaMaker class that has a static method called create which defines the name of the Pizza object as well as the toppings. If the PizzaMaker class did not define create as a static method, we must then create an instance of PizzaMaker in order to use the method. Being able to use Typescript with and without an existing instance of a class make them versatile and flexible. Adding a static properties and methods to a class makes them act like a Singleton, while defining non-static properties and method makes them act like a factory.
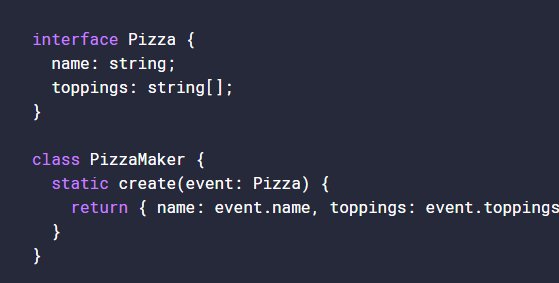
Typescript interfaces are a virtual structure that only exists within the context of Typescript. The compiler uses interfaces only for type-checking purposes. An interface is a structural contract that defines what the properties of an object should have as a name and as a type. In the code below, you will see how the Pizza Interface lists the name and toppings properties and gives them a type. It does not however, create the event or return any objects.
Both interfaces and classes define the structure of an object and can be used interchangeably depending on the situation.
https://toddmotto.com/classes-vs-interfaces-in-typescript
From the blog CS@Worcester – Jarrett's Computer Science Blog by stonecsblog and used with permission of the author. All other rights reserved by the author.