
The blog post titled “Pairwise Testing: A Complete Guide” by Rajkumar (https://www.softwaretestingmaterial.com/pairwise-testing/) delves into the concept of pairwise testing, also known as all-pairs testing. I chose this blog because of its in-depth examples of how to implement pairwise testing. These examples really made it easier to understand how pairwise testing can be used to reduce the amount of test cases while still maintaining high test coverage. The post also outlines the importance of pairwise testing and its advantages. Additionally, it compares pairwise testing with other testing techniques, highlights tools available for automating pairwise testing, and discusses its application in various scenarios.
What is Pairwise Testing?
Pairwise testing is a black-box testing technique used to reduce the number of test cases while still maintaining high test coverage. By focusing on combinations of input pairs, pairwise testing ensures that all possible pairs of input parameters are tested at least once. For example, if you had a program that took three inputs, X, Y, and Z, pairwise testing would create test cases for each combination of input pairs: (X, Y), (X,Z), and (Y,Z). At first glance this may seem like you have to create a ridiculous amount of test cases, but by following the steps for pairwise testing you can see how quickly the number of test cases is reduced.
Applying Pairwise Testing
The first step of pairwise testing is to identify all of your input variables. Next list all possible values for each variable. Variables that have numeric values may be reduced to valid and invalid to begin reducing the number of test cases needed. Then, by creating a table content columns of each variable and its possible outputs, you can get a list of each test case.
This blog’s examples use tables to illustrate how each test case is created by filling in each column one by one.
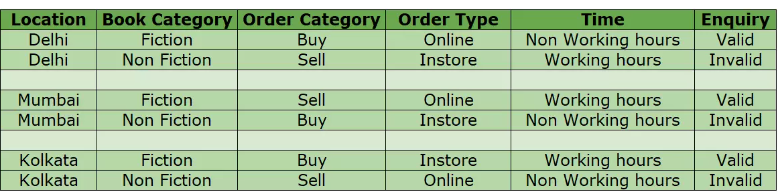
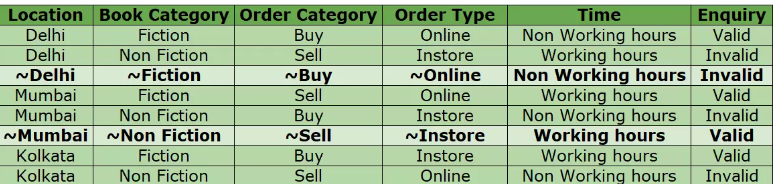
The example from the blog uses a bookstore and creates a table of every variable. In this example you can see how each pair of variables covers all unique combinations except the book category and enquiry. These variables only test fiction with valid and non fiction with invalid. The other columns fixed this by simply reversing the order of one of the test pairs, but doing this would create the same issue for another combination of variables. In this instance two more test cases are added to the list to ensure the unique combination of book category and enquiry.
From the blog CS@Worcester – CS Learning by kbourassa18 and used with permission of the author. All other rights reserved by the author.