
Disclaimer:
This is not explicitly a “guide”. There are far better resources available on this topic; This is simply a discussion about the child_process module.
Anecdotal Background
I’ve been in the process of creating programs to automate the running of my Minecraft Server for my friends and I. In that process, I’ve created a functional system using a node server, a C++ server, and a lot of bash files. While it works, I can’t be sure there aren’t bugs without proper testing. Trust me, nothing about this project has has “doing it properly” in mind.
When learning front-end JavaScript, I recall hearing that it can’t modify files for security reasons. That’s why I was using a C++ server to handle file interactions. Little did I realize node can easily interact with files and the system itself. Once I have the time, I’m going to recreate my set up in one node server. The final “total” set up will involve a heroku node server, a local node server, and a raspberry pi with both a node server (for wake on lan) as well as an nginx server as a proxy for security for the local node servers.
Log
As a bit of a prerequisite, I’ve been using a basic module for a simple improvement on top of console.log. I create a log/index.js file (which could simply be log.js, but I prefer having my app.js being the only JavaScript file in my parent directory. The problem with this approach, however, is that you end up with many index.js files which can be hard to edit at the same time).
Now, depending on what I need for my node project I might change up the actual function. Here’s one example:
module.exports = (label, message = "", middle = "") => {
console.log(label + " -- " + new Date().toLocaleString());
if(middle) console.log(middle);
if(message) console.log(message);
console.log();
}
Honestly, all my log function does is print out a message with the current date and time. I’m sure I could significantly fancier, but this has proved useful when debugging a program that takes minutes to complete. To use it, I do:
// This line is for both log/index.js and log.js
const log = require("./log");
log("Something");
Maybe that’ll be useful to someone. If not, it provides context for what follows…
Exec
I’ve created this as a basic test to see what it’s like to run a minecraft server from node. Similar to log, I created an exec/index.js. Firstly, I have:
const { execSync } = require("child_process");
const log = require("../log");
This uses the log I referenced before, as well as execSync from node’s built in child_process. This is a synchronous version of exec which, for my purposes, is ideal. Next, I created two basic functions:
module.exports.exec = (command) => {
return execSync(command, { shell: "/bin/bash" }).toString().trim();
}
module.exports.execLog = (command) => {
const output = this.exec(command);
log("Exec", output, `$ ${command}`);
return output;
}
I create a shorthand version of execSync which is very useful by itself. Then, I create a variant that also creates a log. From here, I found it tedious to enter multiple commands at a time and very hard to perform commands like cd, as every time execSync is ran, it begins in the original directory. So, you would have to do something along the lines of cd directory; command or cd directory && command. Both of which become incredibly large commands when you have to do a handful of things in a directory. So, I created scripts:
function scriptToCommand(script, pre = "") {
let command = "";
script.forEach((line) => {
if(pre) command += pre;
command += line + "\n";
});
return command.trimEnd();
}
I created them as arrays of strings. This way, I can create scripts that look like this:
[
"cd minecraft",
"java -jar server.jar"
]
This seemed like a good compromise to get scripts to look almost syntactically the same as an actual bash file, while still allowing me to handle each line as an individual line (which I wanted to use so that when I log each script, each line of the script begins with $ followed by the command). Then, I just have:
module.exports.execScript = (script) => {
return this.exec(scriptToCommand(script));
}
module.exports.execScriptLog = (script) => {
const output = this.execScript(script);
log("Exec", output, scriptToCommand(script, "$ "));
return output;
}
Key Note:
When using the module.exports.foo notation to add a function to a node module, you don’t need to create a separate variable to reference that function inside of the node module (without typing module.exports every time). You can use the this keyword to act as module.exports.
Conclusion
Overall, running bash, shell, or other terminals in node isn’t that hard of a task. One thing I’m discovering about node is that it feels like every time I want to do something, if I just spend some time to make a custom module, I can do it more efficiently. Even my basic log module can be made far more complex and save a lot of keystrokes. And that’s just a key idea in coding in general.
Oh, and for anyone wondering, I can create a minecraft folder and place in the sever.jar file. Then, all I have to do is:
const { execScriptLog } = require("./exec");
execScriptLog([
"cd minecraft",
"java -jar server.jar"
]);
And, of course, set up the server files themselves after they generate.
From the blog CS@Worcester – The Introspective Thinker by David MacDonald and used with permission of the author. All other rights reserved by the author.
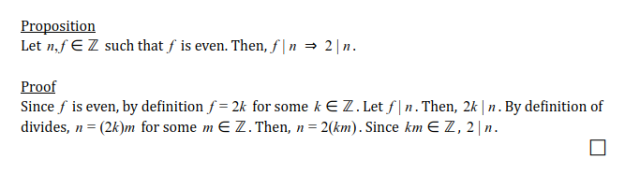
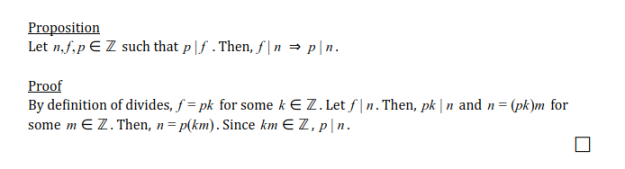
 In this final installment of my individual apprenticeship patterns, I think an important one to write about would be Find Mentors. To summarize the main point of this one, I would say that it encourages people to observe their role and their surroundings to see where they can find the most value from learning or use their resources. It encourages you to look at things from one level back instead of blindly jumping into something right away.
In this final installment of my individual apprenticeship patterns, I think an important one to write about would be Find Mentors. To summarize the main point of this one, I would say that it encourages people to observe their role and their surroundings to see where they can find the most value from learning or use their resources. It encourages you to look at things from one level back instead of blindly jumping into something right away. Over the past two weeks, my team continued to discuss what we are working on as usual. We have come to the conclusion that we will add our Search Bar component once there are updates and more of a base to work off of. This was concluded after we realized that the process would be much more efficient. The parameters and details on the search bar would be harder to figure out without making up a base anyways.
Over the past two weeks, my team continued to discuss what we are working on as usual. We have come to the conclusion that we will add our Search Bar component once there are updates and more of a base to work off of. This was concluded after we realized that the process would be much more efficient. The parameters and details on the search bar would be harder to figure out without making up a base anyways. For my second-to-last individual apprenticeship pattern, I have decided to go with something a little more relevant to my current situation–relating to starting my career post-graduation.
For my second-to-last individual apprenticeship pattern, I have decided to go with something a little more relevant to my current situation–relating to starting my career post-graduation.